


流计算:让数据价值即时释放

K小二
关于流计算
流计算是面向流式数据的计算,即对持续不断产生的数据流进行实时采集、处理、分析与输出,最终将处理结果写入目标表。流计算的核心是 “边产生数据边处理”,而非等待数据全部存储后再批量计算。因此,流计算的一大关键优势就是——能够极大地缩短从数据产生到获取洞察之间的时间,在更短时间内挖掘数据价值。
为什么需要流计算?
一、传统架构局限性大
延迟高、吞吐低
传统批处理延迟>5s,难以应对百万级 TPS 吞吐,数据延迟导致业务决策滞后,错失市场机会。
响应慢,缺乏灵活性
静态数据处理模式难以应对动态业务变化,缺乏实时告警和即时响应能力。
二、实时数据处理需求激增
业务决策实时化
智能制造、智慧能源等领域需在秒级内完成数据清洗、异常检测并触发告警,延迟容忍度极低。
数据价值时效性
设备故障预测等场景要求对最新数据即时分析,历史批处理模式无法满足业务敏捷性需求。
多系统协同需求
实时处理结果需同步推送至其它业务系统,要求数据通道具备低延迟订阅能力。
KaiwuDB 的流计算设计理念与架构
一、核心设计理念
✅ 计算 - 存储融合
摒弃 “存储 - 传输 - 计算” 分离模式,通过 “本地计算” 将流处理逻辑嵌入存储层,如边缘节点直接执行振动数据异常检测(WHERE vibration > 阈值)。
✅ 边缘 - 云端协同
根据数据访问频率动态调整存储层级,边缘节点预处理后仅上传聚合结果(如每小时均值)。
二、数据处理流程
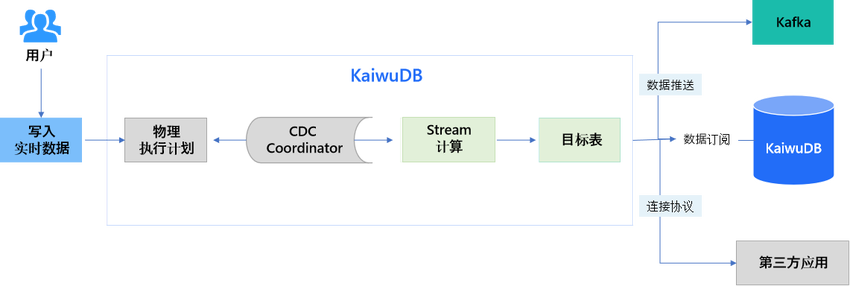
KaiwuDB 使用 SQL 定义实时流变换,当数据被写入流的源表后,数据会被以定义的方式自动处理,并根据定义的触发模式向目的表推送结果,替代了传统复杂流处理系统(如 Kafka、Flink),在高吞吐的数据写入的情况下,提供毫秒级的计算结果延迟。
KaiwuDB 流计算核心功能
一、触发模式
• 立即触发:当有新数据写入时,就会立即触发流式计算。
• 窗口函数触发:实时数据满足窗口(滑动窗口、会话窗口、状态窗口)条件,聚合窗口正常关闭并触发计算。
二、数据处理范围
支持 where 进行行级条件过滤、标量计算、分组聚合查询、窗口计算。
三、数据处理策略
• 断点数据处理策略:当用户启动一个处于停止状态的流计算时,系统会检查是否存在断点数据(未处理数据)并使用流计算最低水位线标识断点数据的范围并进行相应的处理。
• 历史数据处理策略:用户可通过 PROCESS_HISTORY 参数控制是否处理时序表中的存量数据,默认情况下,流计算只处理任务开启后新写入的数据。
• 乱序数据处理策略:用户可以通过 SYNC_TIME 参数指定流计算的乱序数据时间范围。
• 过期数据处理策略:如果新入库的数据落入了已关闭的聚合窗口,则称为过期数据。系统默认丢弃过期数据,用户也可通过将参数设置为 off 实现对对应窗口数据的重新加载并计算。
四、目标端
经过流计算后的处理结果既可以写入时序目标表,也可写入目标关系表。
应用场景与价值
📝 部分典型场景

💡 应用价值
• 数据预处理与降维
入库前开展全流程数据预处理,通过精准数据清洗(剔除噪声、修正偏差)、智能插值补全(填补缺失值)、时序聚合降采样(将秒级高频数据优化聚合成分钟级)等操作,既大幅提升数据洁净度与一致性,为后续分析提供高质量可信输入,又有效压缩数据存储体量、降低计算复杂度,显著节省硬件存储与算力资源成本。
• 预计算加速决策
基于业务场景预设的指标定义规则,对流式原始数据进行实时预聚合与中间结果缓存,查询时直接调用预处理后的聚合结果,无需触发全量数据重算。这一机制将数据分析模式从传统 “事后复盘” 升级为 “事中即时干预”,助力业务决策响应速度从分钟级压缩至秒级甚至毫秒级,大幅提升核心业务的决策敏捷性。
• 实时监控与告警
依托流计算持续迭代的计算能力,对持续流入的高频数据流进行毫秒级连续监测与智能判断。一旦数据满足预设阈值规则,或被机器学习模型识别为异常模式,将立即触发多级告警通知,同时可联动执行预定义的自动化响应动作,真正实现 “异常发现即行动”,构建高效的异常处置闭环。